7 Days to Lift: A Mission in Microcode
Extending the Hex-Rays Decompiler to Support Intel AVX Instructions
Recently I came across a special binary that was compiled to run on a fixed, well-defined set of modern computer hardware. This rather large binary performs many physics simulations via floating-point computations, emitted strictly as instructions from Intel’s Advanced Vector Extensions (AVX).
While IDA Pro has excellent support decompiling ‘legacy’ SSE (floating-point) instructions, it makes no effort to generate higher level pseudocode for AVX instructions. In this post, we will demonstrate how the Hex-Rays decompiler can be extended to support new or otherwise unsupported instructions using the microcode API.
The practical application of this research has been packaged and released as a plugin called MicroAVX.
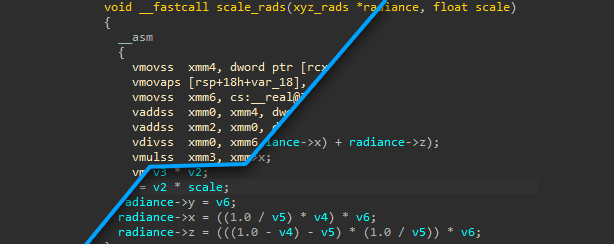
Decompiling AVX instructions by extending the Hex-Rays decompiler
The Hex-Rays Microcode
In 2018, Hex-Rays released IDA Pro 7.1. This was the first version of IDA to expose the decompiler’s internal microcode. This gave researchers access to richer forms of analysis (dataflow, value/type speculation) and the ability to augment the logic of the decompiler at a much lower level than previously possible.
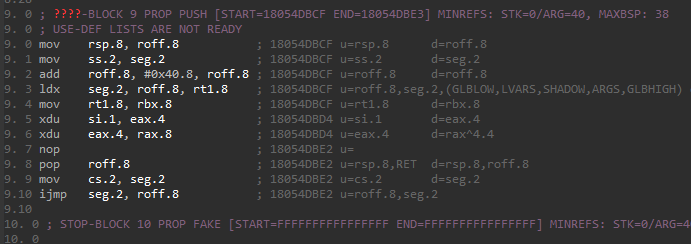
The Hex-Rays microcode makes up a RISC-like intermediate language
The Hex-Rays microcode is an intermediate language (IL). Like most IL’s, its purpose is to provide a portable and architecture-agnostic platform suitable for program analysis. By lifting compiled code to an intermediate language, Hex-Rays can apply a generic set of rules and analysis algorithms to decompile code from any architecture.
At this point, there are a number of existing resources that discuss the Hex-Rays microcode and its implementation in great detail [1] [2] [3] [4] so we will simply move on to the problem at hand.
Unsupported ‘External’ Instructions
Out of the box, the Hex-Rays x64 decompiler does not support AVX instructions. This is not unreasonable, because AVX usage is still relatively rare. When present, most applications include both SSE (legacy) and AVX (modern) versions of the relevant functions to ensure compatibility with CPU’s that predate AVX (2011).
Since the decompiler does not know how to ‘lift’ AVX instructions to the Hex-Rays microcode, the pseudocode will simply inline their assembly. Sometimes this is okay, but other times it can be rather confusing, if not misleading:
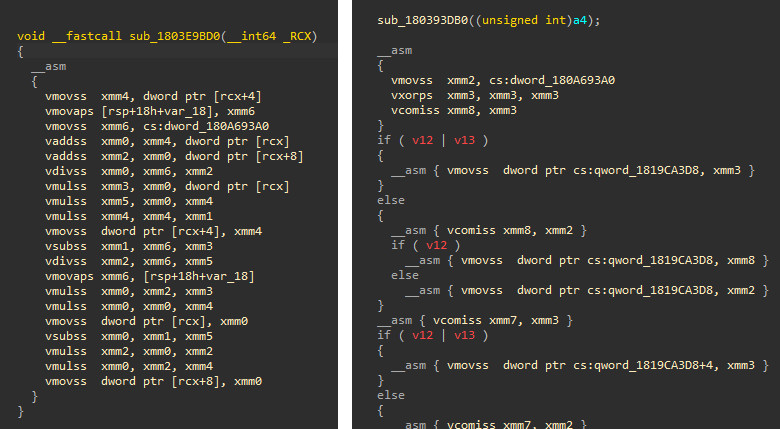
Two seperate examples of the Hex-Rays decompiler inlining unsupported AVX instructions
To take a look under the hood of the decompiler, we can use the genmc plugin. This plugin makes it easy to inspect the Hex-Rays microcode at various stages of the decompilation pipeline. This tool is highly recommended, if not necessary for developing effectively on the microcode API.
Inspecting the microcode for the AVX functions shown above, we can see that the decompiler emits a micro-instruction called ext to indicate an ‘external’ instruction that it does not know how to handle.
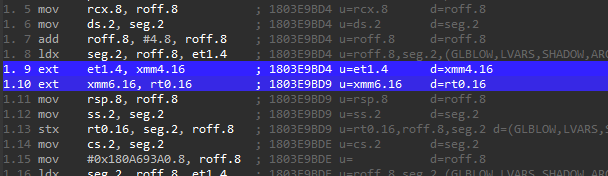
The Hex-Rays microcode denotes 'unsupported' instructions using the 'ext' micro-opcode
With the help of a small script, we can dump every instruction from the database that the decompiler cannot lift. This is done by asking the microcode API to generate the initial microcode for each function, and scraping out any ‘external’ instructions from the generated microcode.
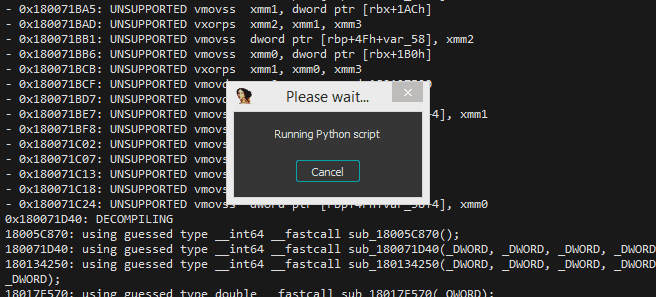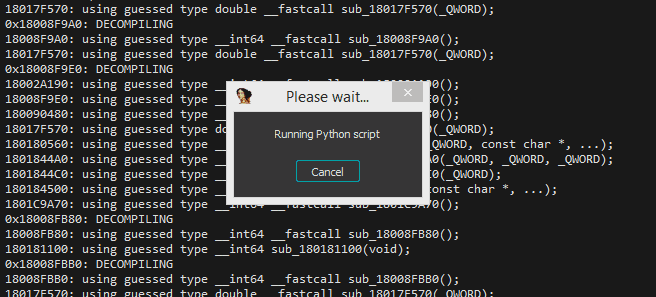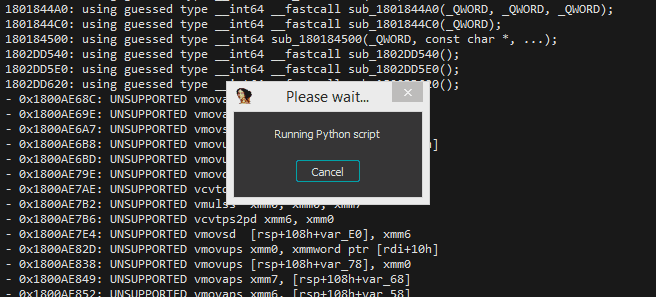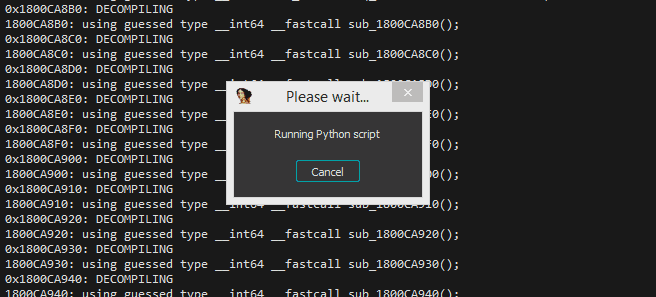
Scraping all the unsupported instructions from the database
The script collects some stats, telling us there are 121 unsupported instructions used by 8148 unique functions. It also dumps out an ordered listing of the unsupported instructions based on how many unique functions use each one. This will help us prioritize which instructions we should focus on lifting first.
Hooking Microcode Generation
The Hex-Rays SDK (and more specifically, hexrays.hpp) is the best source of information for developing microcode or decompiler based extensions. Within this header file we found that Hex-Rays documents a convenient mechanism to perform what they call non-standard microcode generation:
//-------------------------------------------------------------------------
/// Generic microcode generator class.
/// An instance of a derived class can be registered to be used for
/// non-standard microcode generation. Before microcode generation for an
/// instruction all registered object will be visited by the following way:
/// if ( filter->match(cdg) )
/// code = filter->apply(cdg);
/// if ( code == MERR_OK )
/// continue; // filter generated microcode, go to the next instruction
struct microcode_filter_t
{
/// check if the filter object is to be appied
/// \return success
virtual bool match(codegen_t &cdg) = 0;
/// generate microcode for an instruction
/// \return MERR_... code:
/// MERR_OK - user-defined call generated, go to the next instruction
/// MERR_INSN - not generated - the caller should try the standard way
/// else - error
virtual merror_t apply(codegen_t &cdg) = 0;
};
The SDK states that by implementing a microcode filter, we can receive callbacks as the decompiler is generating the microcode for each instruction that falls within a decompilation request. This is an ideal place for us to install a custom lifter that will help the decompiler ‘fill in the blanks’ at the lowest level.
Using the python microcode bindings, we can start building out a simple lifter by subclassing microcode_filter_t. The following template demonstrates how we can cleanly map an unsupported instruction of interest (eg, vxorps) to a function that will be dedicated to lifting that instruction:
class AVXLifter(ida_hexrays.microcode_filter_t):
"""
A Hex-Rays microcode filter to lift AVX instructions during decompilation.
"""
def __init__(self):
super(AVXLifter, self).__init__()
self._avx_handlers = \
{
ida_allins.NN_vxorps: self.vxorps,
# TODO: hook other AVX instructions...
}
def match(self, cdg):
"""
Return true if the lifter supports this AVX instruction.
"""
return cdg.insn.itype in self._avx_handlers
def apply(self, cdg):
"""
Generate microcode for the current instruction.
"""
return self._avx_handlers[cdg.insn.itype](cdg, cdg.insn)
def vxorps(self, cdg, insn):
"""
Generate microcode for the 'vxorps' instruction.
"""
pass # TODO: lift the 'vxorps' instruction
Since we are hooking the decompiler’s initial code generation phase, we are able to ‘get in on the ground floor’. This means that the microcode generated by our lifter will get to ride upwards through the entire analysis and optimization pipeline that makes up the decompiler.
Not only are we extending the decompiler to support new instructions, but we will get to take full advantage of the powerful analysis that Hex-Rays will layer on top of it. In the next section, we will walk through the process of lifting one AVX instruction to the Hex-Rays microcode.
Lifting ‘vxorps’
For this example, we will be lifting the AVX instruction vxorps as it is quite simple. We will be using details scraped from the Intel PDFs to help us understand the semantics of the instruction and lift it to the Hex-Rays microcode.
Copy pasting from the link above, we can roughly summarize vxorps to the following:
VXORPS xmm1, xmm2, xmm3/m128
VXORPS ymm1, ymm2, ymm3/m256
[vxorps] performs a bitwise logical XOR of the [four or eight] packed single-precision
floating-point values from the first source operand and the second source operand,
and stores the result in the destination operand ...
As part of the decompiler’s codegen callback, we are provided with a decoded instance of the vxorps instruction. The following python snippet shows how we can start to break down the decoded instruction as part of the translation to Hex-Rays microcode:
def vxorps(self, cdg, insn):
"""
VXORPS xmm1, xmm2, xmm3/m128
VXORPS ymm1, ymm2, ymm3/m256
"""
# determine if this is a 128bit operation, or 256bit operation
op_size = XMM_SIZE if is_xmm_reg(insn.Op1) else YMM_SIZE
# op3 -- m128/m256
if is_mem_op(insn.Op3):
r_reg = cdg.load_operand(2)
# op3 -- xmm3/ymm3
else:
r_reg = ida_hexrays.reg2mreg(insn.Op3.reg)
# ...
Since the third operand to vxorps can vary between a register or memory load, we must lift them differently based on their type. A ‘processor register’ can easily be converted to a ‘microcode register’ using the function reg2mreg(), whereas load_operand() can be used to automatically transform a memory operand into a ‘temporary’ register.
After translating Op1 and Op2 using the same functions as described above, we are ready to emit a micro-instruction for the explicit ‘XOR’ operation performed by vxorps:
# ...
# op2 -- xmm2/ymm2
l_reg = ida_hexrays.reg2mreg(insn.Op2.reg)
# op1 -- xmm1/ymm1
d_reg = ida_hexrays.reg2mreg(insn.Op1.reg)
# emit 'd_reg = l_reg ^ r_reg'
cdg.emit(ida_hexrays.m_xor, op_size, l_reg, r_reg, d_reg, 0)
# ...
Using the codegen object is the easiest way to emit new micro-instructions. In this example, we ask the codegen to emit the micro-instruction m_xor for us, passing it our three lifted micro-registers as its operands.
The structure of each micro-instruction is unique, and well-defined by the mcode_t enum in the Hex-Rays SDK header hexrays.hpp. In addition, there are more advanced (and flexible) methods to emit microcode as documented by the SDK, but they will not be covered here.
Putting everything together, this is what our completed lifter looks like for the vxorps instruction:
def vxorps(self, cdg, insn):
"""
VXORPS xmm1, xmm2, xmm3/m128
VXORPS ymm1, ymm2, ymm3/m256
"""
# determine if this is a 128bit operation, or 256bit operation
op_size = XMM_SIZE if is_xmm_reg(insn.Op1) else YMM_SIZE
# op3 -- m128/m256
if is_mem_op(insn.Op3):
r_reg = cdg.load_operand(2)
# op3 -- xmm3/ymm3
else:
r_reg = ida_hexrays.reg2mreg(insn.Op3.reg)
# op2 -- xmm2/ymm2
l_reg = ida_hexrays.reg2mreg(insn.Op2.reg)
# op1 -- xmm1/ymm1
d_reg = ida_hexrays.reg2mreg(insn.Op1.reg)
# emit 'd_reg = l_reg ^ r_reg'
cdg.emit(ida_hexrays.m_xor, op_size, l_reg, r_reg, d_reg, 0)
# clear upper 128 bits of ymm1
if op_size == XMM_SIZE:
clear_upper(cdg, d_reg)
# return success
return ida_hexrays.MERR_OK
For more advanced examples of lifting to the Hex-Rays microcode, please check out the MicroAVX plugin that has been released alongside this post. Some of the more interesting handlers demonstrate how to allocate scratch registers for complex operations, or emit intrinsic calls.
Aliasing Instructions
Generally speaking, the AVX instruction set supersedes the ‘legacy’ SSE instructions. As a result, there are at least some number of instructions that the Intel manual claims to be virtually identical (for our use case) in both form and operation between the two extensions. A good example of this is the float comparison instruction comiss.
The Hex-Rays decompiler knows how to lift the SSE instruction comiss, but it has no knowledge of the AVX encoded vcomiss. For all intents and purposes, these instructions are equivalent… and we can trick the decompiler into lifting the AVX form the same as it would the SSE form using the following technique:
def vcomiss(self, cdg, insn):
"""
VCOMISS xmm1, xmm2/m32
"""
insn.itype = ida_allins.NN_comiss
return ida_hexrays.MERR_INSN
During the codegen callback, we can ‘modify’ the decoded instruction. By changing the itype (instruction type) field, we simply ‘alias’ the decoded instruction to the SSE form comiss and return a failure code MERR_INSN. This will tell Hex-Rays that our lifter did not generate microcode for this instruction.
After calling all the registered microcode filters, Hex-Rays will attempt to lift the instruction. Since the decoded instruction now ‘appears’ to be a comiss instruction, it will succeed. This trick seems to work great, but it should be used sparingly as it is undocumented and possibly unsupported.
Decompiling AVX with MicroAVX
Over the course of one week, I developed a small plugin called MicroAVX based on the material covered in this post.
This plugin seamlessly extends the Hex-Rays decompiler to lift 35 of the 121 AVX instructions scraped out of the binary described at the start of this post. With this plugin installed, the number of unique functions in this IDB containing ‘unsupported’ instructions dropped from 8148 to just 510, a ~93% decrease.
While only a proof of concept, the plugin demonstrates real promise. The quality of the decompilation can be quite stunning, and it reflects highly on the flexibility of the Hex-Rays decompiler:
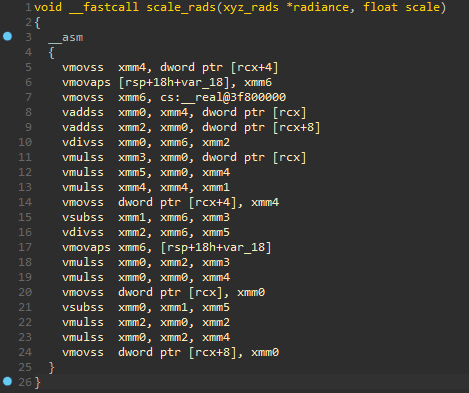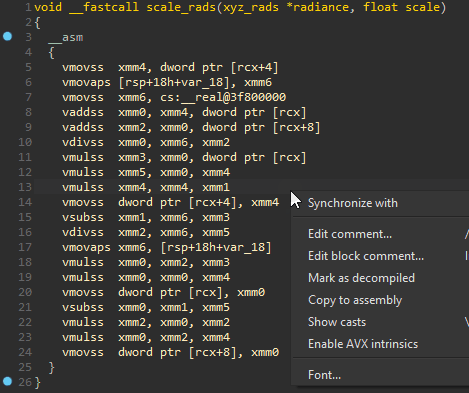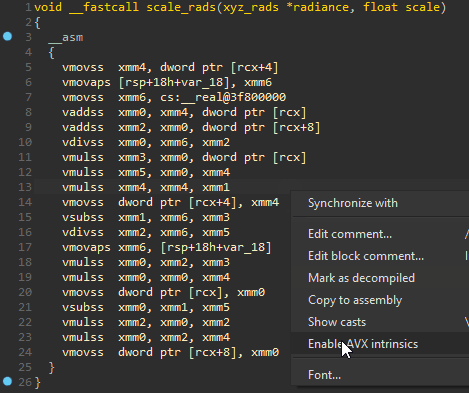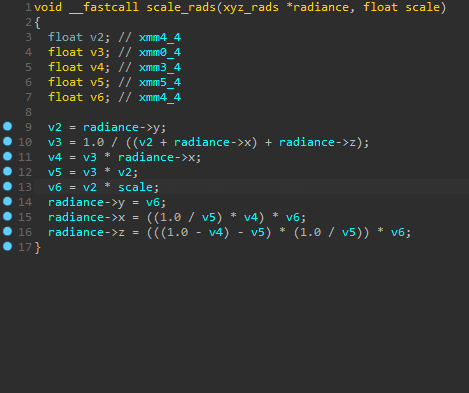
Decompiling some simple float based AVX math using MicroAVX

Decompiling a function that performs float comparisons using AVX instructions
This again highlights the importance of establishing proper tooling when preparing for long-term research projects.
A few dozen hours spent developing this lifter will translate directly to hundreds (if not thousands) of hours saved for the group of individuals that will be researching this binary over the course of several months.
Conclusion
In this post, we demonstrated how the Hex-Rays decompiler can be extended to support new or unknown instructions using its microcode API. This makes it possible to lift previously unsupported instructions to the Hex-Rays microcode, dramatically improving the decompilation of functions containing unsupported code.
Our experience developing for these technologies is second to none. RET2 is happy to consult in these spaces, providing plugin development services, the addition of custom features to existing works, or other unique opportunities with regard to security tooling. If your organization has a need for this expertise, please feel free to reach out.